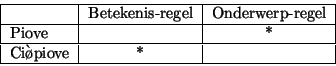Volgende: 6. Processing reflexive ``him'' Omhoog: Link Vorige: 4. Over de LOT
Wat is de overeenkomst tussen het lezen van een handgeschreven adres op een envelop en het redeneren over een aantal stellingen? In de cognitiewetenschap en de kunstmatige intelligentie worden cognitieve processen over het algemeen onderverdeeld in twee soorten. Aan de ene kant zijn er cognitieve processen die betrekking hebben op het ontdekken van patronen in waarnemingen. Het herkennen van de letters van een handgeschreven adres op een envelop is hier een voorbeeld van. Het herkennen van het gezicht van Maxima of de vijfde symfonie van Beethoven zijn andere voorbeelden. Aan de andere kant zijn er cognitieve processen die gebaseerd lijken te zijn op de toepassing van symbolische regels. Redeneren wordt wel gezien als zo'n regelgestuurd proces, net zoals taal. Op basis van deze tweedeling lijkt er dus weinig overeenkomst te zijn tussen het lezen van een handgeschreven adres en het redeneren over stellingen. Deze twee vaardigheden worden blijkbaar gestuurd door fundamenteel verschillende cognitieve processen. Toch zijn ze niet zo verschillend als ze lijken.
In het verleden is wel getracht om taken zoals het herkennen van de letters van een stuk handgeschreven tekst te modelleren met behulp van regels. Dit bleek echter op grote problemen te stuiten. Het bleek onmogelijk om een lijst van kenmerken op te stellen waaraan een letter zou moeten voldoen om gecategoriseerd te worden als bijvoorbeeld een A.
Toch hebben mensen over het algemeen verbazingwekkend weinig moeite met het lezen van een stuk handgeschreven tekst, de echt onleesbare hanepoten daargelaten. Dit komt omdat mensen niet alleen gebruik maken van de plaatselijke kenmerken van de letters, bijvoorbeeld de aan- of afwezigheid van een dwarsstreepje of een ronding. Mensen maken ook gebruik van de context. Die context bestaat uit de omringende letters, kennis over wat een mogelijk woord zou kunnen zijn, verwachtingen over de resulterende betekenis, etcetera.
Aangezien er grote variatie is tussen dezelfde letters van verschillende schrijvers en zelfs tussen letters van dezelfde schrijvers bij verschillende gelegenheden, is het onwaarschijnlijk dat mensen waargenomen letters herkennen door ze te vergelijken met in het geheugen opgeslagen kopieën van letters. Deze methode staat wel bekend als template matching. Noch het gebruik van regels die betrekking hebben op de onderscheidende kenmerken van letters noch template matching biedt dus een goede invalshoek voor de modellering van letterherkenning. Om deze reden maken veel automatische schriftherkenners gebruik van patroonherkenning. Een waargenomen patroon wordt door een dergelijk computerprogramma opgebroken in zijn samenstellende delen of kenmerken. Deze kenmerken wijzen in de richting van bepaalde letters of spreken juist de keuze voor een bepaalde letter tegen. De letter die het best correspondeert met al deze waargenomen kenmerken en met alle informatie die de context levert, wordt uiteindelijk gekozen. Dit proces wordt wel optimalisatie genoemd. Op basis van een aantal soms strijdige kenmerken wordt de letter gekozen die het best voldoet aan al deze kenmerken. Dit is dan de optimale keuze. Er is geen betere keuze, hoewel de optimale letter niet alle onderscheidende kenmerken hoeft te bezitten. Zo kan een letter ook herkend worden als een A als de twee schuine poten elkaar bovenaan niet helemaal raken.
Er wordt wel beweerd dat patroonherkenning en optimalisatie processen zijn die kenmerkend zijn voor het lagere niveau van representatie. Op het hogere niveau van representatie zouden we regelgestuurde processen aantreffen, waarbij abstracte symbolen door middel van regels gemanipuleerd zouden worden. Het lagere niveau, dat direct gekoppeld zou zijn aan de fysieke eigenschappen van onze hersenen, zou simpelweg de abstracte symbolische processen van het hogere niveau uitvoeren. Maar kijken we nu naar de cognitieve vaardigheid van het redeneren, dan blijkt het vermogen van mensen om abstracte symbolen te manipuleren aan de hand van symbolische regels maar weinig robuust te zijn. Net als letterherkenning kan het menselijk redeneren sterk worden beïnvloed door de aanwezigheid van contextinformatie en de beschikbaarheid van overige kennis. Dit komt goed naar voren in een serie experimenten uit de cognitieve psychologie waarin het menselijk redeneervermogen is onderzocht.
In het oorspronkelijke experiment van Peter Wason (1966) kregen proefpersonen een aantal kaarten voorgelegd met één letter of één cijfer op de ene kant (bijvoorbeeld de kaarten met A, D, 4 en 7). De andere kant van de kaart was niet zichtbaar.
De proefpersonen kregen te horen dat op elke kaart aan de ene kant een letter en aan de andere kant een getal stond. De proefpersonen kregen bovendien een stelling voorgelegd: ``Als op de ene kant van een kaart een klinker staat, dan staat op de andere kant van de kaart een even getal''. Ze moesten vervolgens beslissen welke kaarten in ieder geval moesten worden omgedraaid om uit te vinden of de stelling klopt of niet. De stelling kan worden weergegeven als een logische implicatie: als p dan q. In de propositielogica is deze implicatie onwaar als p waar is en tegelijkertijd q onwaar is. Dit komt overeen met de situatie waarin een kaart aan de ene kant een klinker bevat en aan de andere kant een oneven getal. In alle andere gevallen is de implicatie waar. Zouden de proefpersonen logisch redeneren, dan zouden ze de kaarten met A en 7, en alleen deze kaarten, noemen. Echter, slechts 4 procent van de proefpersonen bleek in staat om het juiste antwoord te geven.
In een vervolgexperiment toonden Richard Griggs en James Cox (1982) aan dat wanneer proefpersonen over een concrete in plaats van een abstracte stelling moesten redeneren, veel proefpersonen wel het juiste antwoord gaven.
Hun stelling was: ``Als iemand bier wil drinken, dan moet hij of zij ouder zijn dan 19 jaar''. De proefpersonen kregen te horen dat de kaarten informatie bevatten over een persoon: aan de ene kant van de kaart hoe oud hij of zij is en op de andere kant wat hij of zij drinkt. Ze moesten zich voorstellen dat ze een politieagent waren die moest controleren of mensen zich wel hielden aan bovengenoemde regel. Opnieuw moesten proefpersonen beslissen welke kaarten in ieder geval moesten worden omgedraaid om uit te vinden of mensen zich hielden aan de regel of niet. Veel proefpersonen (74 procent) gaven hier wel het juiste antwoord, namelijk de kaarten met bier en 16 jaar. Blijkbaar passen mensen niet simpelweg abstracte regels toe, maar gebruiken ze alle informatie die ze maar tot hun beschikking hebben om tot een oplossing te komen voor een probleem. Sterker nog, ze lijken deze contextinformatie soms echt nodig te hebben om tot het juiste antwoord te komen. In dit opzicht lijkt de manier waarop mensen redeneren dus op de manier waarop mensen handgeschreven letters herkennen.
In het laatste experiment hielp de concrete informatie proefpersonen om het correcte antwoord te geven dat overeenkwam met de regels van de logica. Het omgekeerde komt ook voor: mensen trekken soms conclusies die logisch gezien niet gerechtvaardigd zijn, maar die corresponderen met wat ze geloven of willen geloven. Neem bijvoorbeeld het volgende syllogisme:
Alle dingen die een motor hebben gebruiken olie.
Alle auto's gebruiken olie.
Conclusie: Auto's hebben een motor.
De conclusie van dit syllogisme volgt logisch gezien niet uit de voorafgaande twee zinnen. Toch trekken veel mensen deze conclusie. Blijkbaar kan kennis van de context van de redenering en kennis van de wereld het redeneerproces zowel de goede als de verkeerde kant op sturen.
Aan de ene kant zijn er dus cognitieve processen die gebaseerd lijken te zijn op het ontdekken van patronen in waarnemingen. Aan de andere kant lijken er cognitieve processen te zijn die gebruik maken van symbolische regels. Maar hebben die patronen wel louter betrekking op processen op een laag niveau van representatie, zoals wel wordt beweerd? En zijn die symbolische regels wel zo hard en worden ze wel zo onafhankelijk van andere kennis uitgevoerd als over het algemeen wordt aangenomen? Is het inderdaad zo dat ons brein twee fundamenteel heel verschillende cognitieve processen uitvoert, of zijn er toch sterke overeenkomsten tussen patroonherkenning en optimalisatie enerzijds en regelgebaseerde processen anderzijds? In de rest van dit artikel zullen we ons concentreren op taal.
Het gebruik van taal wordt binnen de taalkunde over het algemeen gezien als een regelgebaseerd proces. Het streven van veel taalkundigen is dan ook om regels te formuleren die de vorm, het gebruik en de verwerving van taal kunnen beschrijven en verklaren. Begin jaren 90 suggereerden Alan Prince en Paul Smolensky (Prince & Smolensky 1993, 1997) echter dat het combineren van klanken tot woorden en het combineren van woorden tot zinnen wel eens gestuurd zou kunnen worden door een proces van optimalisatie.
Dit betekent overigens niet dat Prince en Smolensky de beschrijving van taal door middel van regels verwerpen. De belangrijkste eigenschap van de door Prince en Smolensky geïntroduceerde Optimaliteitstheorie is dat taalregels niet hard zijn maar zacht, dat wil zeggen schendbaar. Een taalregel mag volgens deze visie geschonden worden, maar alleen als daarmee aan een belangrijkere taalregel kan worden voldaan. Taalregels zijn dus niet allemaal even belangrijk of even sterk. In plaats daarvan zijn sommige taalregels sterker dan andere. Omdat taalregels bovendien zo algemeen mogelijk dienen te zijn, zijn ze potentieel strijdig. Een grammatica bestaat op deze manier uit een verzameling potentieel strijdige taalregels. Die taalregels worden niet stap voor stap toegepast, zoals meestal bij regels het geval is. Taalregels worden juist gelijktijdig toegepast op mogelijke woorden of mogelijke zinnen. Omdat de regels vaak strijdig zijn, kan niet altijd aan alle regels tegelijk worden voldaan. In dit geval is het belangrijker om te voldoen aan een sterkere regel dan aan een zwakkere. Mogelijke woorden of mogelijke zinnen concurreren met elkaar. De optimale vorm is de vorm die het best voldoet aan de hele verzameling van taalregels. Dit is dan de uiteindelijke of grammaticale vorm.
Taalregels verschillen dus in sterkte en kunnen gerangschikt worden naar sterkte. Een belangrijk uitgangspunt van Optimaliteitstheorie is dat talen verschillen door een andere rangschikking van de regels. Dit kan worden geïllustreerd aan de hand van een eenvoudig voorbeeld. In het Nederlands moet een zin altijd een onderwerp bevatten, zelfs al draagt dat onderwerp niets bij aan de betekenis van de zin:
a. Het regent.
b. *Regent.
Om deze reden is zin (a), die een loos onderwerp bevat, in het Nederlands de enige mogelijkheid om uit te drukken dat het regent, en is zin (b) ongrammaticaal. In het Italiaans daarentegen is het omgekeerde het geval. Als je in het Italiaans wilt zeggen dat het regent, dan moet je het onderwerp weglaten:
a. Piove.
b. *Ciò piove.
Een eenvoudige verklaring voor dit verschil is te geven in Optimaliteitstheorie. Stel dat beide talen beschikken over dezelfde twee regels, namelijk de onderwerpregel en de betekenisregel.
Onderwerpregel: Elke zin moet een onderwerp hebben.
Betekenisregel: Elk woord in de zin moet bijdragen aan
de betekenis van de zin.
In het Nederlands is het belangrijker dat elke zin een onderwerp heeft dan dat elk woord in de zin bijdraagt aan de betekenis van de zin. De onderwerpregel is dus in het Nederlands sterker dan de betekenisregel. In onderstaande figuur is dit weergegeven door de onderwerpregel in de bovenste rij links te plaatsen van de betekenisregel. Des te verder naar links, des te sterker de regel. Onder elkaar in de eerste kolom staan alle mogelijke manieren om de betekenis uit te drukken dat het regent. Deze mogelijke zinnen zijn met elkaar in competitie. Uiteindelijk wint een van deze mogelijke zinnen. De winnaar is de vorm die het best voldoet aan alle regels. De input voor dit optimalisatieproces is dus een betekenis, en de output is de optimale vorm voor die betekenis.
De mogelijke zin ``Regent'' voldoet aan de betekenisregel. Immers, er staan geen woorden in de zin die niet bijdragen aan de betekenis. Maar helaas schendt de zin ``Regent'' de sterkere onderwerpregel. Dit is weergegeven door een asterisk te plaatsen in het hokje dat bij de rij van ``Regent'' en de kolom van de onderwerpregel hoort. Er is een andere mogelijke zin die beter voldoet aan bovenstaande twee regels, namelijk ``Het regent''. Deze mogelijke zin schendt wel de betekenisregel, maar voldoet aan de sterkere onderwerpregel. Omdat een schending van de betekenisregel minder erg is dan een schending van de onderwerpregel, is deze zin dus de optimale manier om de gegeven betekenis uit te drukken. Dit wordt weergegeven door het wijzende handje. De schending van de onderwerp-regel is de mogelijke zin ``Regent'' dus fataal geworden. Door deze schending is de zin ``Het regent'' een betere uitkomst. Zo'n fatale schending wordt aangeduid met een uitroepteken.
Al eerder merkten we op dat het in het Italiaans belangrijker lijkt dat elk woord in de zin bijdraagt aan de betekenis van de zin dan dat elke zin een onderwerp heeft. Dit duidt erop dat in het Italiaans de betekenisregel sterker is dan de onderwerpregel.
Bovenstaande figuur laat zien dat de mogelijke zin ``Piove'' hierdoor de optimale zin is. Deze voldoet aan de sterkere betekenisregel, zij het ten koste van een schending van de zwakkere onderwerpregel. Schending van de sterkere betekenisregel wordt de mogelijke zin ``Ciò piove'' fataal, hoewel deze vorm wel aan de zwakkere onderwerp-regel voldoet.
Door de vorm van een woord of zin te beschouwen als de uitkomst van een proces van optimalisatie, kan een verklaring worden gegeven voor de intuïtie dat verschillende en soms zelfs strijdige factoren van invloed lijken te zijn op de uiteindelijke vorm van een woord of zin. Bovenstaand voorbeeld laat bovendien zien dat verschillen tussen talen verklaard kunnen worden vanuit dezelfde verzameling taalregels, door aan te nemen dat talen verschillen in de relatieve sterkte van die regels.
Een vrij recent idee (zie o.a. Hendriks & De Hoop 2001) is dat dit proces van optimalisatie ook wel eens verantwoordelijk zou kunnen zijn voor de uiteindelijke betekenis die we toekennen aan een zin. Neem het volgende tekstje:
a. Sollicitanten voldoen nooit aan alle eisen.
b. Drie werden afgewezen.
De tweede zin, zin (b), is eigenlijk incompleet. Van het onderwerp ontbreekt een zelfstandig naamwoord. De zin ``Drie werden afgewezen'' deelt iets mee over drie zaken, maar gaat het nu over drie voorstellen, drie minnaars, drie sollicitanten, of zelfs over drie geheel andere zaken? De meeste mensen zullen van mening zijn dat zin (b) iets zegt over drie sollicitanten. Immers, die sollicitanten worden in de voorafgaande zin genoemd. Echter, het idee dat een ontbrekend zelfstandig naamwoord altijd geïnterpreteerd moet worden als een daarvoor genoemd zelfstandig naamwoord is niet helemaal correct. Kijk maar naar het volgende tekstje:
a. Zes sollicitanten toonden belangstelling.
b. Drie werden afgewezen.
In zin (b) gaat het niet over drie sollicitanten in het algemeen, maar over drie van de sollicitanten die belangstelling hadden getoond. Dit duidt erop dat niet alleen het naamwoord uit de voorgaande zin van belang is voor de interpretatie van het ontbrekende naamwoord in zin (b), maar ook de rest van de zin. Het naamwoord sollicitanten activeert een verzameling van sollicitanten. Het predikaat verkleint deze verzameling blijkbaar tot die elementen die ook deel uitmaken van de verzameling die wordt uitgedrukt door het predikaat. De voorkeursinterpretatie van de incomplete NP in (b) is dus dat deze betrekking heeft op de doorsnede van de verzameling van sollicitanten (A) en de verzameling van individuen die belangstelling toonden (B), dat wil zeggen op de verzameling A Ç B. Dit wordt uitgedrukt door de antecedentregel.
Antecedentregel: Kies als het antecedent van een
incomplete NP de verzameling A Ç B van de voorgaande zin.
De antecedentregel doet echter niet altijd de juiste voorspellingen voor wat betreft de interpretatie van een incomplete NP. De antecedentregel zou voorspellen dat de interpretatie van (9b) is dat drie van de sollicitanten die belangstelling toonden werden afgewezen. Echter, de voorkeursinterpretatie van de meeste mensen is dat drie andere sollicitanten werden afgewezen.
a. Twee sollicitanten toonden belangstelling.
b. Drie werden afgewezen.
De door de antecedentregel voorspelde interpretatie is in strijd met ons gezond verstand: als er slechts twee sollicitanten belangstelling toonden, dan kunnen niet drie daarvan worden afgewezen. Immers, twee is minder dan drie. Eenzelfde effect is te zien in het volgende tekstje:
a. Zes sollicitanten werden aangenomen.
b. Drie werden afgewezen.
Als een sollicitant wordt aangenomen, dan wordt deze niet afgewezen. Omdat aangenomen worden en afgewezen worden twee tegengestelde eigenschappen zijn, kunnen ze niet gelijktijdig het geval zijn. De voorkeursinterpretatie van (10b) is dan ook dat het hier gaat om drie andere sollicitanten. Blijkbaar is ons gezond verstand een sterkere factor in de interpretatie van incomplete zinnen dan de antecedentregel. Het effect van gezond verstand op interpretatie kunnen we weergeven in de vorm van een regel.
Gezond-verstand-regel: Vermijd tegenstrijdigheden.
De interactie tussen de antecedentregel en de gezond-verstand-regel kan op dezelfde manier worden weergegeven als de interactie tussen de onderwerpregel en de betekenisregel. In onderstaande tabel is dit gedaan voor de zin ``Drie werden afgewezen'' wanneer deze volgt op de zin ``Zes sollicitanten werden aangenomen''. De input van dit optimalisatieproces is dus zin (10b) in de context van zin (10a), en de output is de optimale interpretatie voor deze zin in deze context.
Twee mogelijke interpretaties voor zin (b) zijn weergegeven in de eerste kolom. De interpretatie dat het gaat om drie van de sollicitanten die werden aangenomen voldoet aan de antecedentregel. De verzameling van sollicitanten die werden aangenomen is de doorsnede van de verzameling van sollicitanten en de verzameling van individuen die werden aangenomen. Echter, deze interpretatie is in strijd met de gezond-verstand-regel. Omdat de gezond-verstand-regel sterker is dan de antecedentregel, voldoet een andere interpretatie beter aan deze twee regels, namelijk de interpretatie dat het in zin (b) gaat om drie andere sollicitanten. Deze interpretatie is dus de optimale interpretatie.
Je zou je nu kunnen afvragen of talen ook verschillen in de rangschikking van interpretatieregels, net zoals ze volgens de uitgangspunten van Optimaliteitstheorie verschillen in de rangschikking van vormregels. Daarnaast is natuurlijk een interessante kwestie hoe interpretatieregels van een verschillende aard zich tot elkaar verhouden. De gezond-verstand-regel is geen pure taalregel, maar lijkt eerder een algemene vuistregel die van toepassing is op veel onderdelen van het menselijk gedrag. Hoe verhouden dergelijke algemene vuistregels zich tot de pure taalregels? En hoe verhouden regels die betrekking hebben op een bepaald aspect van taal (bijvoorbeeld de intonatie van de zin of de talige context) zich tot regels die betrekking hebben op andere aspecten van taal (bijvoorbeeld de syntactische structuur van de zin of de betekeniseigenschappen van woorden)? Vormt syntactische structuur wel de basis voor de interpretatie, of is het mogelijk dat andere regels soms sterker zijn dan syntactische regels en is syntactische structuur slechts een van de vele beperkingen op interpretatie?
In september 2002 is een landelijk project van start gegaan onder de titel ``Conflicts in interpretation'', waarin onder andere deze vragen centraal staan. Dit project wordt gefinancierd in het kader van het NWO/Cognitie-programma. Dit programma heeft tot doel het cognitiewetenschappelijk onderzoek in Nederland te stimuleren. Drie verschillende universiteiten nemen deel aan het project: de Universiteit Utrecht (met Henriëtte de Swart en Joost Zwarts), de Katholieke Universiteit Nijmegen (met Helen de Hoop en Irene Krämer) en de Rijksuniversiteit Groningen (met Petra Hendriks en Gerlof Bouma). Binnen het project zal de komende vier jaar door middel van taaltypologisch, experimenteel en computationeel onderzoek getracht worden een antwoord te vinden op bovenstaande vragen.
Een ding lijkt in ieder geval duidelijk te zijn: mocht het zo zijn dat interpretatie via een proces van optimalisatie verloopt, dan zijn we weer een stapje dichterbij de overbrugging van de veronderstelde kloof tussen regels en patronen. We zouden dan opnieuw een cognitieve vaardigheid hebben blootgelegd waarbij geen sprake is van harde regels. In plaats daarvan hebben we dan te maken met zachte regels of neigingen, die betrekking hebben op diverse soorten van beschikbare informatie en die gezamenlijk resulteren in een bepaald betekenispatroon. Hier is een duidelijke overeenkomst zichtbaar met de eerder genoemde cognitieve vaardigheden van gezichtsherkenning, letterherkenning en redeneren. Wellicht zal uiteindelijk zelfs blijken dat alle menselijke cognitieve processen op deze manier verlopen.
Eric Auer 2003-06-18
![\includegraphics[width=3cm,keepaspectratio]{petrahendriks-fig1.eps}](img1.png)
![\includegraphics[width=4cm,keepaspectratio]{petrahendriks-fig2.eps}](img2.png)
![\includegraphics[width=10cm,keepaspectratio]{petrahendriks-fig3.eps}](img3.png)
![\includegraphics[width=10cm,keepaspectratio]{petrahendriks-fig4.eps}](img4.png)